載入中...
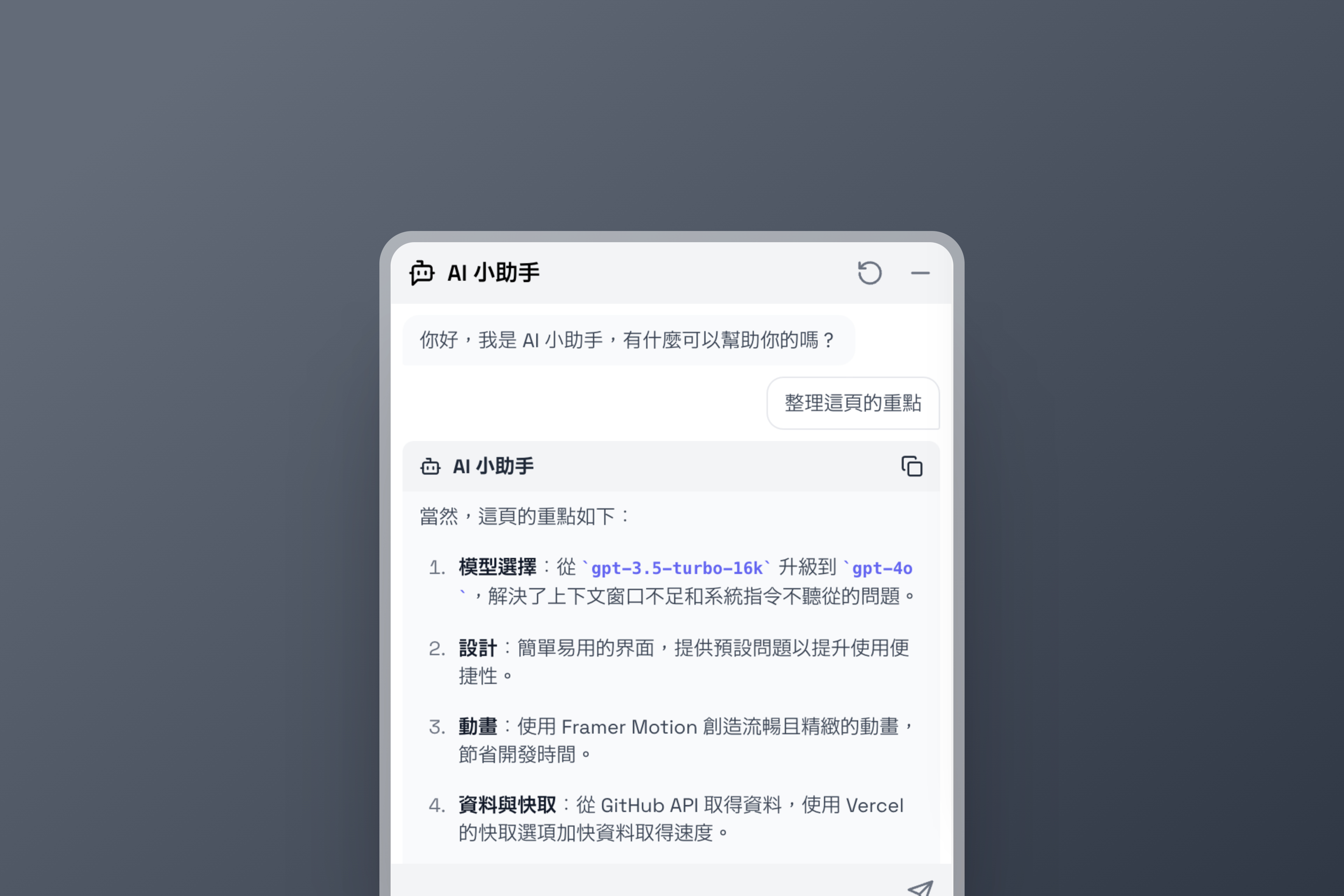
隨著大型語言模型如雨後春筍般一一冒出,我們也在思考在網站部署一個 AI 小助手的可能性,在考慮到價格與需求的平衡後,我們最終使用了 GPT-4o 開發網站小幫手,讓網站可以有個客服讓使用者問答和解釋一些複雜的概念。
從 GPT 3 到 GPT 4o
我們原先使用較為便宜的 gpt-3.5-turbo-16k 模型,但受限於上下文窗口(context window)不足,無法輸入較長的文章,所以換到了 gpt-4o,並解決了原先模型不太聽系統指令(system prompt)的問題。
設計

註:影片經加速處理
我們認為 AI 小幫手應該要能提供給使用者看一眼就知道如何去使用的設計,因此除了基本的聊天界面外,為了讓機器人可以輕鬆被使用,也提供了幾個預設問題讓使用者能夠選擇並與 LLM 深入問答。
動畫
Framer Motion 的 Layout animations 讓我們可以以少量的程式碼撰寫流暢又精緻的動畫,並節省了很多時間,也不必撰寫複雜且難以維護的 CSS 樣式
資料與快取
由於在 Vercel 上我們的資料是被編譯好的前端網站,透過前端傳遞給後端又感覺不是很安全,所以我們直接從 GitHub API 從我們的 Repository 取得原始 markdown 格式的資料。
這麼做有兩個好處:
- 我們的 API 不會被濫用,因為只能抓取我們存放在 GitHub 中的資料
- Markdown 格式比 HTML 更加節省 token 數量
而在 Vercel 提供了快取選項,在 fetch 選項中加入 cache: 'force-cache' 就會被快取了!透過資料快取我們可以加快取得資料的時間,也不會因重複請求讓 GitHub API 額度被用光。
AI 快取
由於提供了預設選項,會產生很多內容相同的訊息,因此我們希望相同的請求會被快取並輸出以節省 API 費用,並加快輸出。
我們使用了 Cloudflare 的 AI Gateway 進行快取,這個功能完美解決了我們的需求,並提供了儀表板來監控請求數量和快取比例。
重新串流
使用 AI Gateway 帶來了額外的問題,由於 Cloudflare 會直接一次輸出完整結果,而不像 LLM 那樣逐字輸出的樣子,我們針對文字串流部分的程式碼進行修改,讓文字不會一瞬間回傳整個結果,而是會像原本那樣一個字一個字輸出。
系統指令(system prompt)
透過適當的系統指令,我們可以避免大型語言模型輸出不在網站內的內容,像是「午餐要吃什麼」之類的無關問題,會被模型直接拒絕。
此外也加入了引導,讓使用者切換到對應的頁面進行問答。
費用
相信大家對我們的 AI 小助手的費用相當好奇吧,截至文章撰寫當下:
- 大約有 15.92% 的請求被成功快取
- 在 Open AI 的儀表板中五月總共有 875 個請求
- 使用的 token 數量是 418 萬個
- 五月的總費用是 23.42 美元(大約是新台幣 757 元)
程式碼
AI 網站小幫手的程式碼部分都有開源,分為 前端元件 和 後端 API 兩個部分,你可以根據 CC0 授權協議自由取用!
試試看!
目前 AI 小幫手在部落格、官網和會議記錄網站上都有安裝,你可以點選右下角的機器人按鈕玩玩看!
未來展望
未來我們希望透過 Assistant API 並提供官網所有的文章給 LLM 參考,讓使用者能夠根據整個網站的內容進行提問,而不拘限於目前頁面,並藉此節省 token 費用